APEX URLs and HTML need not be in your SQL report queries

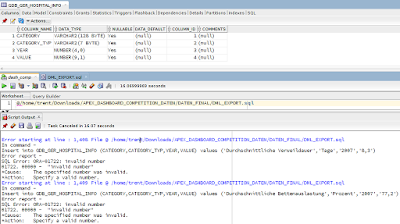
I've seen a few examples recently where people have been embedding URLs and HTML into their SQL queries. I tend to advocate keeping such things out of the query itself and using APEX functionality such as link target and html expressions (in SQL Query column attributes). First example, a full page URL embedded into a column like so (conditionally based on some condition): case when job = 'PRESIDENT' then 'f?p='||:APP_ID||':2:'||:APP_SESSION||'::::P2_EMPNO:'||empno else 'f?p='||:APP_ID||':3:'||:APP_SESSION||'::::P3_EMPNO:'||empno end dest_url Then on the column attributes, you make it a link by specifying the type as a link and the target as a URL specifying the target as #DEST_URL# Taking a look at the URL, we can see there is only one bit changing, and that is the page number. So, we can avoid embedding the whole URL in our query by simply adding a column for our destination page: case when job = 'P